Member-only story
Machine Learning 101 — Classification vs. Clustering
Part of a Series on Machine Learning Concepts
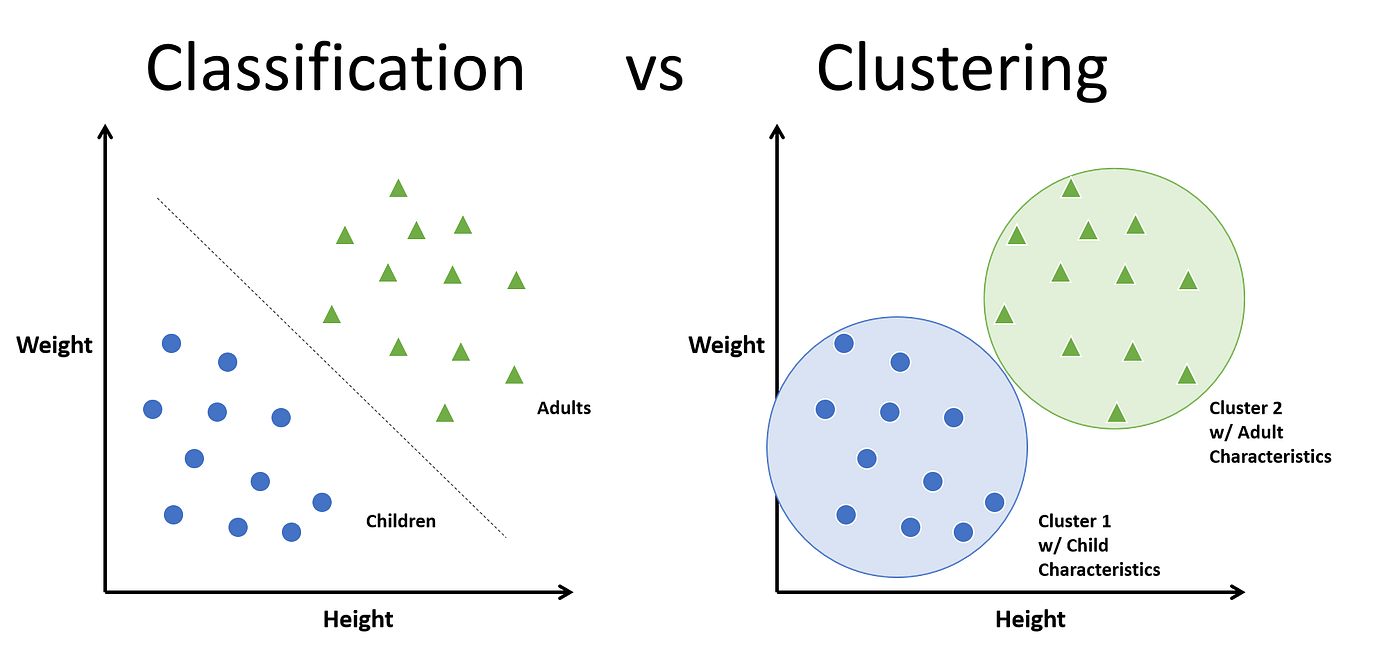
Classification and Clustering are two types of learning methods that attempts to categorize records based on one or more features in the data. While there are similarities in their objectives, their approaches are different.
Classification
Classification uses supervised learning techniques to find the relationship between the feature(s) and the assigned label(s). Upon training with sufficient data samples, the resulting model can be used to predict the label (and probability) that a given data point resembles.
Algorithms:
- Logistic Regression
- Decision Tree/Random Forest
- Neural Networks
- Naive Bayes
- K-Nearest Neighbors
- Support Vector Machines
Common Applications:
- Risk Assessment Model
- Spam Detection
- Fraud Detection
Clustering
Clustering uses unsupervised learning techniques to organize unlabeled data points into homogeneous groups where those within a “cluster” have similarities and “clusters” have dissimilarities. Since data is not pre-labeled, there is no training process. Instead, clusters are created using similarity functions that measure the distance between points. Relative to classification, clustering is considered a less complex approach and well suited for large datasets.
Algorithms:
- K-means
- K-medoids
- Density Based
- Hierarchical
Common Applications:
- Recommender System
- Customer Segmentation
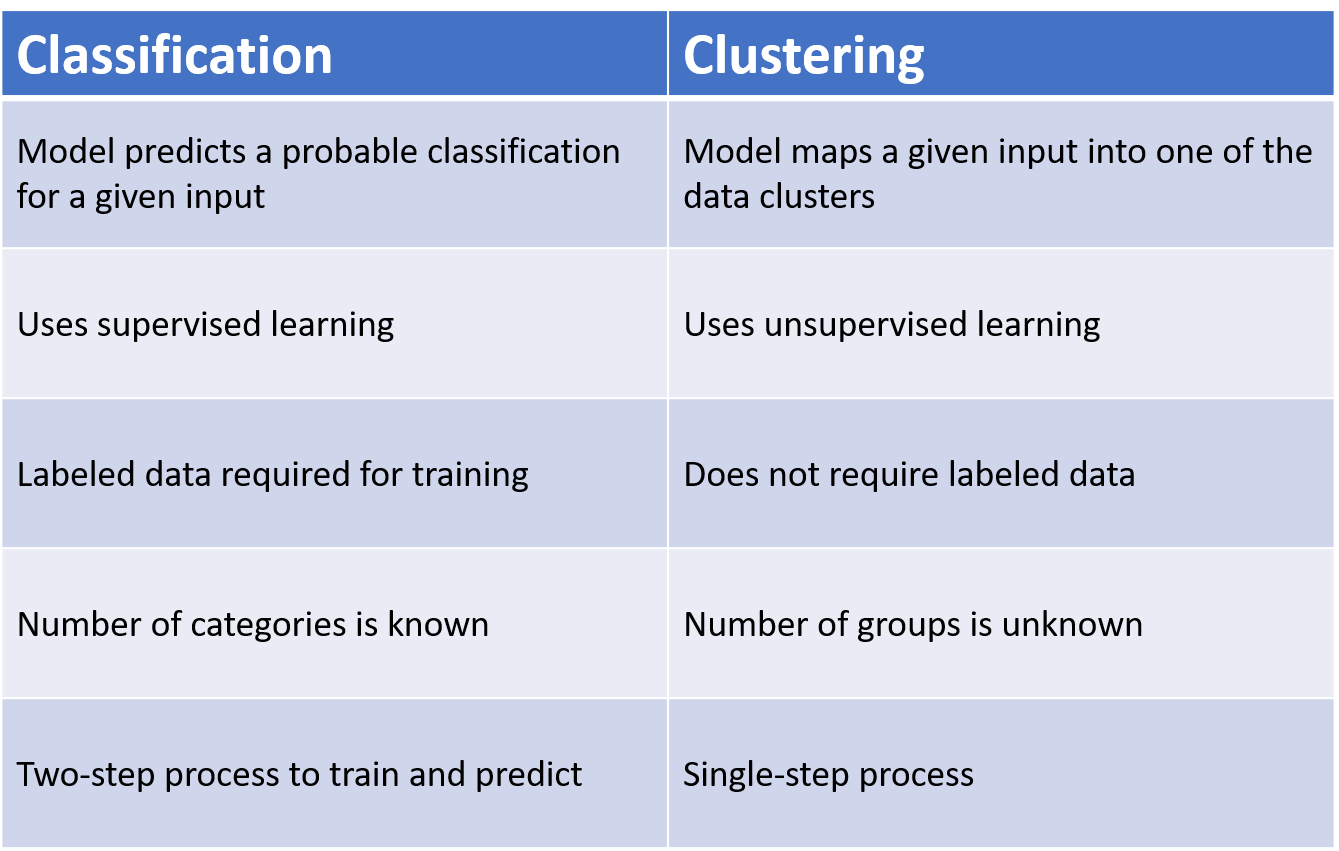
Comparison Chart